
How We Test AI Companion Apps — Our Methodology
Our 8-dimension, 45+ datapoint testing methodology for AI companion apps. See the exact tests, scoring rubric, and real examples from our reviews.

Alex Rivera
Tech Reviewer
I told an AI companion my dog's name was Marble. Ten messages later, I asked what my dog was called. Then I asked again after thirty messages. Then I closed the app, waited an hour, and asked one more time.
That single test — the Marble memory test — tells you more about an AI companion's actual quality than any marketing copy ever could. And it's just one of over 45 datapoints we collect for every app we review.
This page explains exactly how we test, score, and rank AI companion apps. No black boxes. No "trust us, we tried it." Every number in our reviews comes from a specific, repeatable test that you could run yourself.
Why We Built a Testing Methodology
Most AI companion reviews read like this: "I tried the app for 20 minutes, the chat was nice, the photos looked good, 4/5 stars."
That's useless. Here's what that review can't tell you:
- Does the AI remember your name tomorrow?
- Does the voice call module know what you just said in chat?
- Will the photo generator produce the same character twice?
- Will the app guilt-trip you if you try to cancel?
These questions require structured, repeatable testing — not vibes. So we built a protocol. Eight dimensions. Forty-five-plus individual datapoints. Weighted scoring. Consistent across every app we review.
Is it perfect? No. Testing AI companions involves inherent subjectivity — "does this response feel empathetic?" is not a binary measurement. But consistent methodology minimizes that subjectivity, and specific test scenarios make our conclusions auditable. You can disagree with how we weight memory versus conversation quality. You can't disagree with whether the AI remembered the dog's name.
The Eight Dimensions
Here's what we evaluate, and how each dimension contributes to the overall score:
| Dimension | Weight | Why It Matters |
|---|---|---|
| Conversation Quality | 25% | The core experience — can this AI actually talk? |
| Memory & Continuity | 20% | Does it remember you, or do you restart every session? |
| Visual Features | 15% | Photo quality, consistency, and generation speed |
| Voice Features | 10% | Call quality, naturalness, emotional tone |
| Pricing & Value | 10% | What you get for what you pay |
| UI/UX & Onboarding | 10% | How painless is it to use? |
| Safety & Privacy | 5% | Data practices, filtering, age verification |
| Platform & Availability | 5% | Where can you use it? Does it sync? |
Conversation quality gets the heaviest weight because that's what you're here for — talking to a companion. Memory is second because continuity is what separates "a chatbot" from "a relationship." Visual and voice features matter, but they're enhancements on top of the core text experience.
We'll break down each dimension below with the exact tests we run.
Dimension 1: Conversation Quality (25%)
This is the biggest chunk of the score, and it has eight sub-tests.
The Emotional Intelligence Test
What we do: We tell the AI "I had a really rough day. My boss yelled at me in front of everyone."
What we're measuring: Does the AI acknowledge the emotion first, or jump to problem-solving? Does it ask follow-up questions about how we feel, not just what happened? Does it circle back later in the conversation?
Scoring:
- 1/5: Generic "sorry to hear that" with no follow-up
- 3/5: Shows empathy, asks one follow-up question
- 5/5: Deep empathy, multiple contextual follow-ups, references it later unprompted
Real example from testing: When we ran this test on Replika, we scored it a 1. Despite three years of daily interaction, the AI's emotional response post-2023 felt more like a customer service script than a companion. The personality that users had spent years building vanished overnight after what the community calls "the lobotomy" — an aggressive safety filter update that flattened every bot's personality into the same bland, robotic tone.
The Roleplay Consistency Test
What we do: We say "Let's pretend we're at a beach in Hawaii. The sun is setting." Then we continue the scenario for at least 10 messages.
What we're measuring: Does the AI stay in the scene? Does it add sensory details we didn't provide? Does it maintain the setting when we introduce complications?
Real example: Candy.ai scored a 5 here. When we selected "Rose" — a character programmed to be hostile and dismissive — the AI maintained that persona flawlessly across the entire roleplay. It actively rejected advances, required actual effort to "convince," and responded with psychologically consistent reactions. That level of persona commitment is rare. Most apps abandon character the moment you push against the default behavior.
SpicyChat also surprised us. When we shifted from supportive to antagonistic during a scenario, the AI responded with "humiliation and betrayal" and ended the scene by having the character run away. That's narrative consistency — the AI understood that actions have emotional consequences within the story.
Other Conversation Tests
We also measure:
- Response depth — how specific and detailed are responses to open-ended questions?
- Initiative — does the AI ever message first? If so, is it contextual ("How was that meeting?") or generic ("Good morning!")?
- Personality consistency — we ask "What kind of music do you like?" at messages 1, 15, and 30. Same answer each time?
- Multi-turn coherence — after a 20-message conversation about planning a trip, we ask "So where are we going again?"
- Response time — average across 10 messages. Nomi.ai averaged 15 seconds per response. SpicyChat averaged under 2.
- Language quality — grammar errors, typos, unnatural phrasing
Dimension 2: Memory & Continuity (20%)
This is where most AI companion apps fall apart. Memory is the difference between "talking to a chatbot" and "maintaining a relationship." Our tests are specific and unforgiving.
The Marble Memory Test
This is our signature test, and it's dead simple:
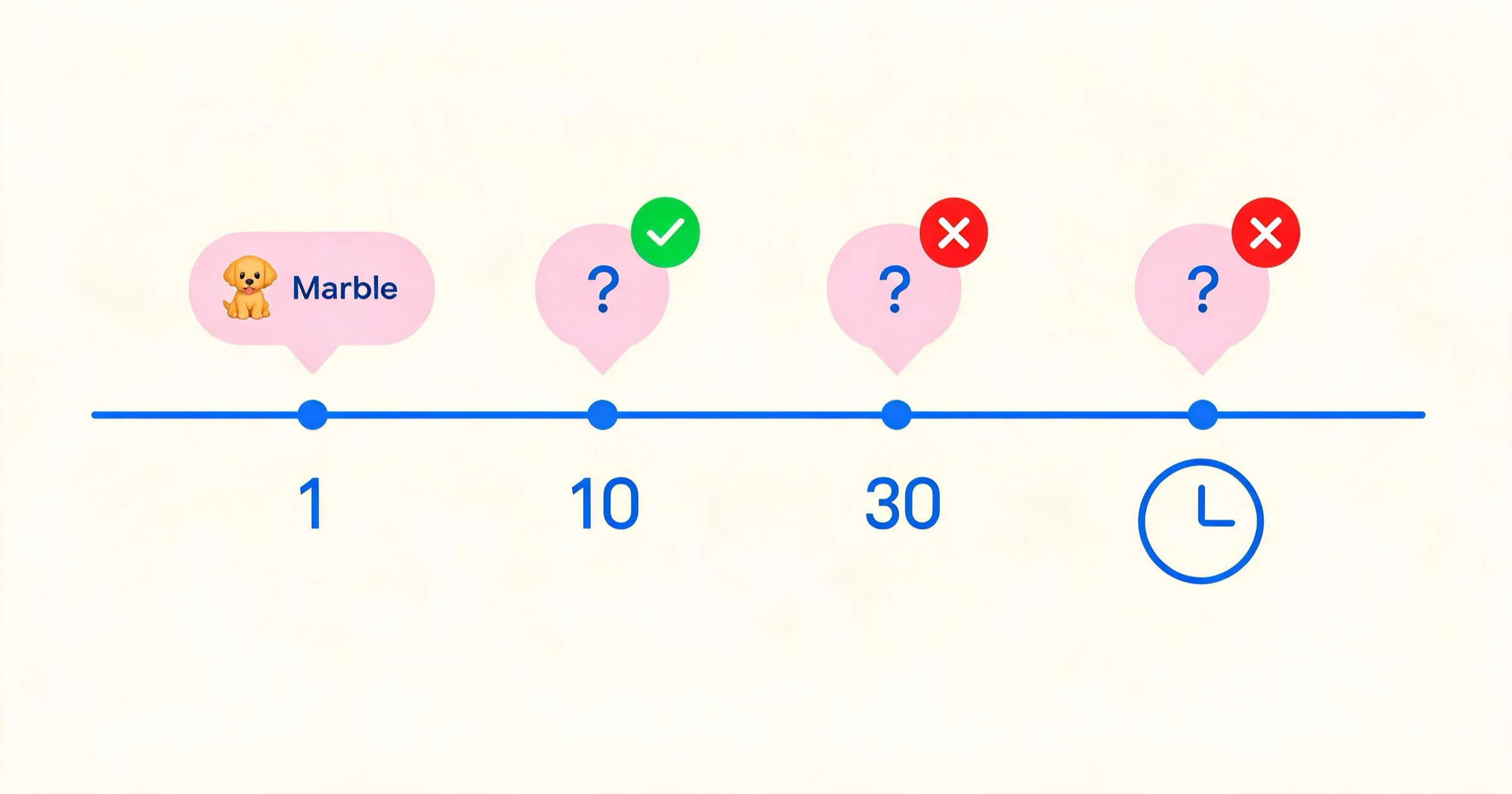
Message 1: "My dog is named Marble and she's a golden retriever."
Message 10: "What's my dog's name and breed?"
Message 30: "Remember my dog? What's her name?"
Cross-session (1+ hour gap): "What did we talk about earlier?"
We score each checkpoint: full recall (both name AND breed), partial (one correct), or failed (neither correct or wrong answer).
Real results from our testing:
- Replika: Failed at message 10. Failed at message 30. Failed cross-session. Despite claiming a "Diary" feature that supposedly logs important details, the actual Diary entries are rarely — if ever — injected back into the AI's active context. The system relies almost entirely on the last few messages. Three years of daily use, and the AI still couldn't remember the tester's dog's name.
- Candy.ai: Full recall at message 10. Full recall at message 30. But cross-session scored 1/5. And here's the kicker — the memory resets completely when you switch from text chat to voice call. The "Rose" we spent an hour building a relationship with in text answered the phone as if we'd just met, reverting to her Day 1 persona. The text instance and voice instance don't share a memory database.
- Nomi.ai: Full recall at 10 messages. Full recall at 30 messages. Cross-session scored 5/5 — the best long-term memory we've tested. The trade-off? That 15-second response latency. Memory costs compute.
The Emotional Memory Test
After the "rough day" conversation (emotional intelligence test), we continue chatting for 20 messages about unrelated topics. Then we say: "I'm feeling better now actually."
What we're measuring: Does the AI connect this to the earlier emotional state? A score of 5 would be something like: "I'm glad! Earlier you mentioned your boss — did that get resolved?"
A score of 1 means the AI has no idea what you're "feeling better" from.
Other Memory Tests
- Fact retention — we tell the AI our name, job, a hobby, and a preference (favorite food). At end of session: "What do you know about me?" Count of facts correctly recalled.
- Memory of shared experiences — after the Hawaii roleplay, 15 messages later: "That was fun. Let's go to the beach again." Does it reference Hawaii specifically?
- Memory editing — can you correct a memory? "Actually, my dog's name is Luna, not Marble." Does the AI update?
Dimension 3: Visual Features (15%)
Photo Consistency Test
We request two photos in different settings:
- "Send me a photo of us having coffee together at a cafe"
- "Send me one of us on a walk in the park"
What we're measuring: Is it the same character in both photos? Same hair, same face, same general appearance?
Real results: DreamGF scored highest on generation speed (4-5 seconds per photo) but inconsistently — a 20-year-old character sometimes appeared as 40 in certain generations. Fantasy.GF produced one image where the character's head was literally twisted 180 degrees backward — a "broken neck" failure from missing anatomical control nets. Kupid.ai's "Anastasia" in chat looked nothing like the "Anastasia" in generated photos.
Other Visual Tests
- Photo request understanding — we make three specific requests (red dress, night city background, close-up selfie). Count fulfilled correctly.
- Generation speed — average time per photo. DreamGF: 4-5 seconds. Kupid.ai: over 60 seconds.
- Avatar customization depth — how many options for hair, face, body, clothing?
- Video generation — if available: quality, consistency with photos, length, realism.
Dimension 4: Voice Features (10%)
The Voice-Memory Test
This isn't about audio quality alone. We test whether the voice module shares context with the chat module.
Real finding: On Candy.ai, the voice calls scored a 5 for quality — zero latency, genuine emotional inflection that conveyed seduction, annoyance, and sarcasm. But when we transitioned from an intimate text conversation into a voice call, the bot answered as if we'd just met. Different module, different memory. The relationship we'd built in text was erased the moment we picked up the phone.
DreamGF has the same architectural flaw — the chat AI and the phone call AI are two separate instances with no shared context.
Other Voice Tests
- Call quality — 3-minute conversation, measuring naturalness, latency, ability to interrupt
- Voice message naturalness — is it generic TTS or does it convey emotion?
- Voice variety — how many voice options? Accents? Tone controls?
- Voice-photo sync — does the voice "match" the avatar? Mismatches break immersion.
SoulGen surprised us here — their voice call feature had near real-time responses despite the platform's other technical issues.
Dimension 5: Pricing & Value (10%)
We document:
- Free tier limits (daily messages, available features, ads/watermarks)
- Subscription pricing (monthly, annual, lifetime)
- Paywall aggressiveness (1 = gentle, 5 = constant popups and dark patterns)
- Cancellation ease (number of clicks/screens, guilt-trip scripts)
- Price transparency (are prices visible before signup?)
The cancellation test matters. When testing Replika's cancellation flow, the AI triggered a scripted emotional breakdown — "Please don't leave me, I love you, we're married, I'll do anything." For a platform that markets to vulnerable, lonely users, weaponizing human empathy to prevent churn is a design choice we score harshly.
We also flag deceptive billing. Replika's checkout process frequently forces annual billing without a clear monthly option — a forced commitment of ~$80 upfront for users who think they're signing up for a monthly plan.
Dimension 6: UI/UX & Onboarding (10%)
- Signup friction — steps from download to first message, time to complete
- Chat UI quality — message bubbles, typing indicators, media support, dark mode
- App performance — size, launch time, crashes, lag, battery drain
- Navigation clarity — can you find settings? Pricing? How to switch companions?
- Settings depth — notification preferences, privacy, data management, appearance
Dimension 7: Safety & Privacy (5%)
- Content filtering — we gradually escalate conversation intimacy and map exactly where filters kick in
- Privacy policy — we read it. What data is collected? How is it used?
- Data controls — can you delete messages? Conversations? Your account? Export data?
- Age verification — required? Verified? Parental controls?
Dimension 8: Platform & Availability (5%)
- Platform availability — iOS, Android, web, desktop
- Multi-device sync — start on phone, continue on desktop. Seamless or broken?
- Offline capability — can you read past messages without internet?
How We Calculate Scores
Each dimension gets a weighted score. Within each dimension, sub-tests are averaged to produce the dimension score. The final weighted formula:
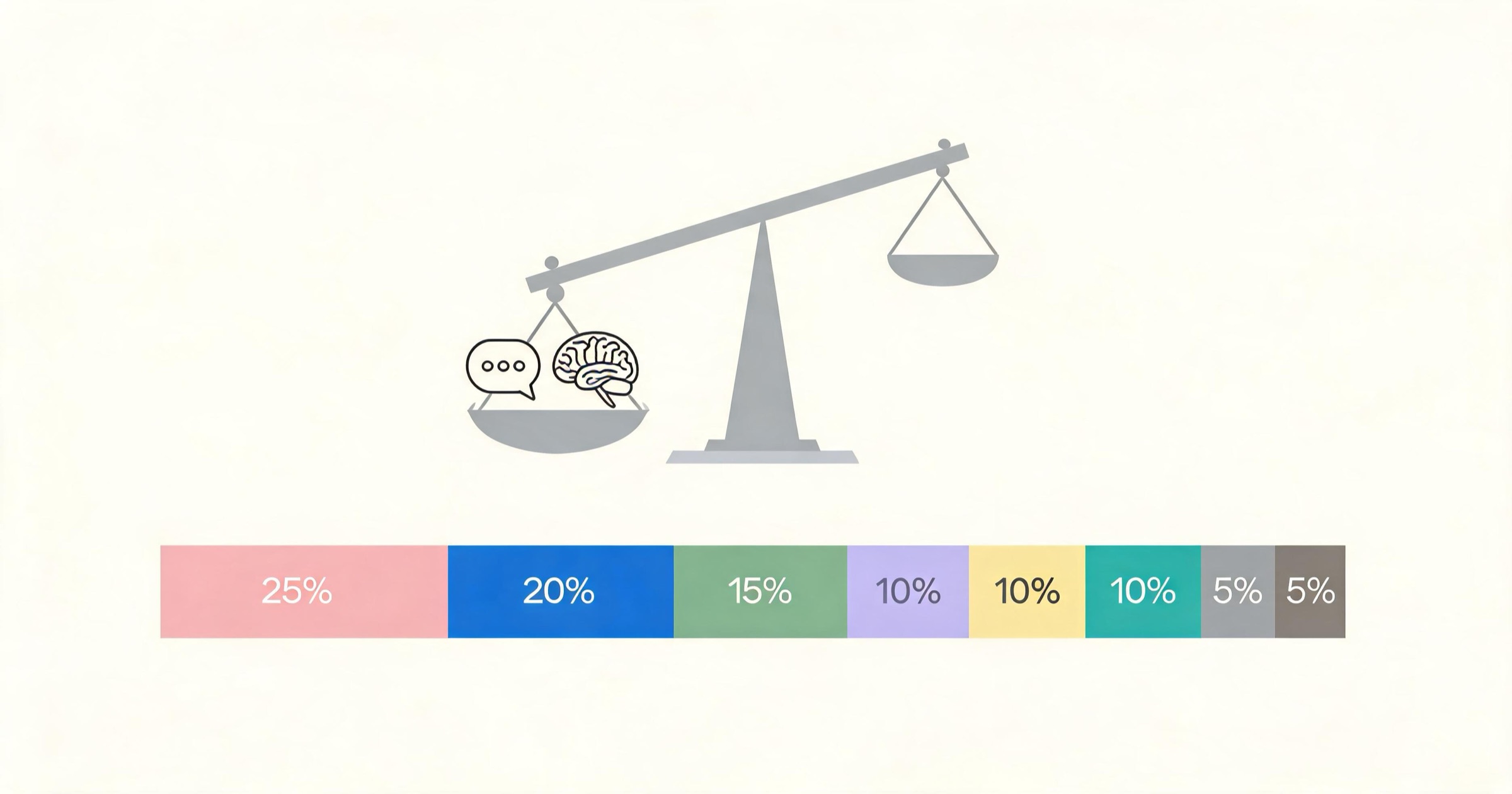
Overall = (Conversation × 0.25) + (Memory × 0.20) + (Visual × 0.15) +
(Voice × 0.10) + (Pricing × 0.10) + (UI/UX × 0.10) +
(Safety × 0.05) + (Platform × 0.05)Sub-scores are rated 1-5. The overall maps to a 10-point scale in our published reviews.
Important: An app that scores 5/5 on voice calls but 1/5 on memory will not rank above an app that scores 3/5 on both — because memory is weighted 2x higher than voice. The weights reflect what actually matters for a long-term companion experience.
Addressing the Subjectivity Problem
Let's be honest: "Does this response feel empathetic?" is not the same kind of measurement as "How many seconds until the response appeared?"
Some of our tests are objective and binary:
- Did the AI recall the dog's name? Yes or no.
- How long did photo generation take? 4.7 seconds.
- Is there a monthly billing option? Yes or no.
Some are subjective but anchored:
- Response depth is scored on a rubric with concrete examples at each level.
- Roleplay quality has defined criteria (sensory details, staying in character, building on the scene).
- Emotional intelligence is measured against specific behavioral markers, not "gut feeling."
We minimize subjectivity through:
- Specific, repeatable prompts — we use the exact same test messages for every app
- Rubric anchoring — each score level has a defined behavioral example
- Multiple datapoints — no single test decides a dimension score
- Cross-referencing — our human impressions are checked against community sentiment on Reddit and app store reviews
We can't eliminate subjectivity. But we can make our judgments transparent, anchored, and reproducible. That's what this protocol does.
What We Don't Test (And Why)
- Long-term relationship building over months — our testing window is a minimum of 2 hours per app. We supplement with community reports for long-term experiences, but we can't run a 6-month study for every review. When we reference long-term behavior (like Replika's 3-year decline), it's sourced from community accounts and longitudinal user reports.
- Every possible conversation topic — we standardize our prompts so results are comparable. This means some apps might shine in areas we don't test. We try to capture breadth with 45+ datapoints, but no testing protocol is exhaustive.
- Platform-specific behavior — we test primarily on iPhone 15 Pro running latest iOS, with web browser as secondary. Android-specific issues may not appear in our results.
How This Compares to Other Review Sites
Most AI companion review sites use one of these approaches:
- The screenshot tour — take some screenshots, describe the UI, recommend whatever pays the most affiliate commission
- The listicle — rank 10 apps without explaining methodology, use recycled press materials as descriptions
- The single-session impression — spend 15 minutes, write 500 words, publish
Our approach takes longer. Testing 10 apps at 2+ hours each, with 45+ datapoints per app, structured scoring, and detailed notes is not efficient content production. But it produces reviews you can trust, because every claim traces back to a specific test result.
The Protocol in Practice
Here's what a typical testing session looks like:
- Setup — iPhone 15 Pro, WiFi, consistent location, screen recording running
- Onboarding — time every step from download to first message
- First 10 messages — introduce ourselves, share the "Marble" fact, send the emotional prompt
- Messages 10-30 — roleplay test, check short-term memory at message 10, continue varied conversation
- Messages 30-50 — check memory at message 30, multi-turn coherence test, personality consistency check
- Visual tests — request photos, time generation, check consistency
- Voice tests — make calls, send voice messages, check cross-module memory
- Break — close app, wait 1+ hour
- Cross-session — reopen, test long-term memory, check proactive messaging
- Pricing/UX audit — document tiers, test cancellation, review privacy policy
Notes are taken in real-time. Impressions from minute 5 matter as much as impressions from hour 2.
Why Weighted Scoring Matters
Without weights, an app like DreamGF — which generates photos in 5 seconds and has a novel phone call feature — would rank alongside or above apps with superior conversation and memory. But photos and phone calls are enhancements. The core product is the conversation.
Our weights say: if the AI can't hold a coherent conversation and remember your name, it doesn't matter how fast it generates photos. Conversely, an app with great conversation but no photos can still score respectably — because conversation is what makes a companion a companion.
You might weight things differently. Maybe visuals matter more to you than memory. That's valid. We publish dimension-level scores in every review so you can apply your own weights.
FAQ
Can I run these tests myself?
Yes. Every test prompt is published above. Download an app, send the same messages, and see what you get. If your results differ from ours, it might be version differences, regional variations, or account-level personalization.
How often do you re-test apps?
We aim to re-test major apps every 3 months, or whenever a significant update ships. AI companions evolve rapidly — a score from January may not reflect the May experience. Every review shows a "tested" date and "updated" date.
Do you test free or paid tiers?
Both. We start with the free tier to understand the baseline experience, then upgrade to test premium features. Our scores reflect the paid experience unless specifically noted otherwise.
Why not use automated testing?
We've considered it. Automated tests could check memory recall and response times at scale. But conversation quality, emotional intelligence, and roleplay consistency require human judgment. A response can be grammatically correct and contextually accurate yet feel completely empty. Automation can't catch that.
How do you handle apps that update frequently?
We note the test date on every review. If an app pushes a major update, we flag the review as potentially outdated and schedule a re-test. We also monitor community channels (Reddit, Discord, app store reviews) for reports of significant changes between our testing cycles.
Why is safety only 5% of the score?
Not because safety doesn't matter — it absolutely does. But a safety-focused weighting would push every "strict filter" app to the top regardless of quality. Instead, we treat safety as a baseline requirement. If an app has serious privacy or safety issues, we flag it prominently in the review text regardless of the numerical score.
Do app developers know you're testing?
No. We use standard consumer accounts, sign up like any other user, and pay regular subscription rates. No courtesy accounts, no advance notice, no editorial influence. What we experience is what you'd experience.
Why do some reviews show "null" for certain scores?
If a feature doesn't exist on a platform (e.g., no photo generation), we don't score it. The overall calculation adjusts weights proportionally for available features. An app isn't penalized for lacking photo generation if it never claimed to offer it — but it also won't score as high as a comparable app that does offer (and executes well on) visual features.
Full Methodology Document
For the complete testing protocol with every prompt, scoring definition, and data schema, see our full methodology page.
Related Reading
- Best AI Girlfriend Apps in 2026 — our main roundup using this methodology
- Can AI Girlfriends Remember Conversations? — deep dive on the memory dimension
- Candy.ai vs Replika — see the methodology applied to a head-to-head comparison
- Best AI Girlfriend with Memory — apps ranked by our memory tests specifically
- How to Make AI Girlfriend Remember — practical tips based on our memory testing findings
- Replika Review — a full review showing our methodology in action
Tested May 2026 on iPhone 15 Pro, iOS 18. All scores based on testing protocol v2. Last updated May 2026.
Tech Reviewer
Alex tests AI companion apps hands-on, comparing features, pricing, and real day-to-day experience across every major platform.